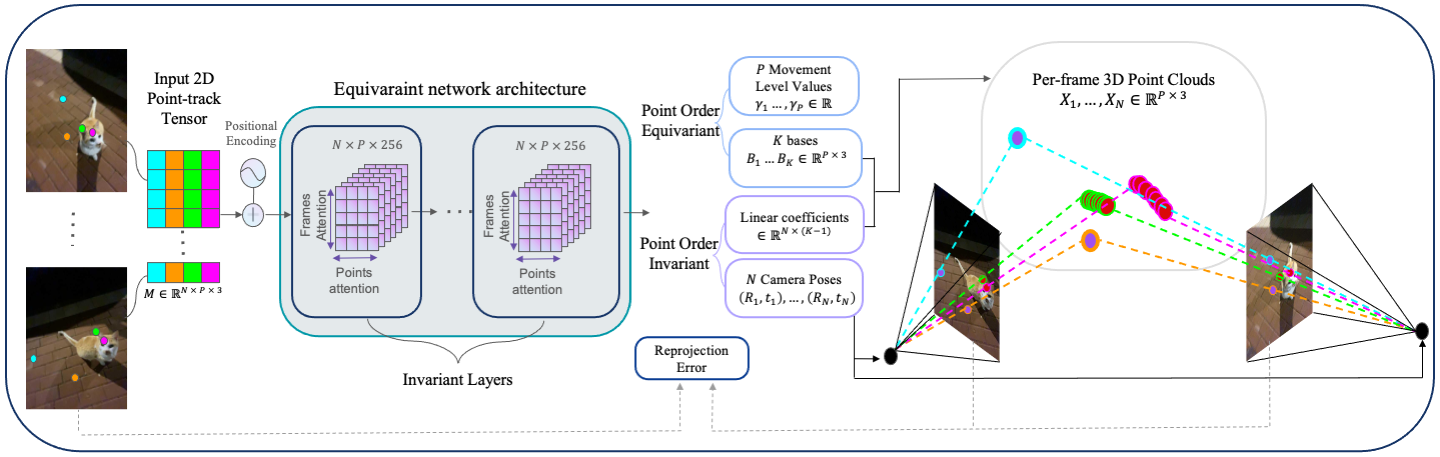
We tackle the long-standing challenge of reconstructing 3D structures and camera positions from several scene images. The problem is particularly hard when objects are transformed in a non-rigid way. Current approaches to this problem make unrealistic assumptions or require a long optimization time. We present TracksTo4D, a learning-based approach to infer 3D structure and camera positions from in-the-wild videos. Specifically, we build on recent progress in point tracking, to extract long-term point tracks from videos, and learn class-agnostic features.
We then design a deep equivariant neural network architecture (Figure 2), that maps the point tracks of a given video into corresponding camera poses, 3D points, and per-point non-rigid motion level values. Training on pet videos, we observe that by just "watching" point tracks in videos, our network learns to infer their 3D structure and the camera motion.
Our model is trained on the Common Pets dataset using only 2D point tracks extracted by CoTracker, without any 3D supervision by simply minimizing the reprojection errors. We evaluate our method on test data with GT depth maps and demonstrate that it generalizes well across object categories. With a short bundle adjustment, we achieve the most accurate camera poses compared to previous methods, all while running faster. More specifically, compared to the state-of-art, we reduced the Absolute Translation Error by 18%, the Relative Translation Error 21%, and the Relative Rotation Error by 15%. Moreover, our method produces depth accuracy comparable to the state-of-the-art method, while being ~x10 faster. We also demonstrate a certain level of generalization to entirely out-of-distribution inputs.
 NVIDIA Research
NVIDIA Research